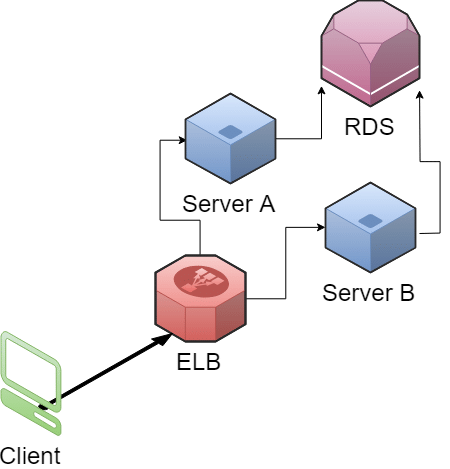
Today we’ll be going over some of potential strategies for hosting WordPress on AWS in a scalable and highly available fashion.
This is a follow up to my previous article on the problems you’ll face implementing a WordPress architecture on AWS. If you haven’t read that yet, I’d suggest taking a short moment to do so.
Let’s dive right in!
Please note: This article is not intended to be a play by play tutorial. There are trade offs to each of the following solutions and it will be your job to determine what the best fit for your use case is.
What we need to cover
We want to have a WordPress site hosted on AWS that will be both highly available and support EC2 auto-scaling functionality.
There are a few things we’ll need to cover to end up with a setup that covers these bases.
- By default, WordPress stores user uploaded content (Images, videos, etc) on the web/app servers file system. These should instead be stored in an Object Store like S3.
- The webroot on the server contains plugins, themes, and things like the wp-config as well. This is a harder problem to solve (well) and there are numerous solutions.
Object Storage
Unless you use a solution that syncs the webroot folder across servers (We’ll get into that later) you will need to store any user uploaded files in an Object Store. Since we’re using AWS, the easy choice is S3. It’s inexpensive and has wide plugin support.
I’ve found numerous options for plugins but the two that seem to be the most actively updated are:
The configuration for each of these plugins (and many like them) is incredibly simple. It normally involves creating an S3 bucket and an IAM user with the appropriate credentials then setting those in the plugin. Due to the simple nature, this is an exercise left to the reader.
WP Offload Media Lite
WP Offload Media Lite seems like a solid solution but the Lite Version does not support importing existing images without upgrading to the paid version. If this is a problem you may want to consider the next option.
Media Cloud
Media Cloud not only handles newly uploaded files, it will also allow you to move over already uploaded files at no added cost.
This plugin seems intended to integrate with a tool called Imgix but it appears this integration is completely optional.
Since this option is completely free and supports uploading exists files at no cost, this will likely be your best bet.
An important note: Both of the above plugins support the AWS Cloudfront CDN and it would be a good idea to implement it. This can both help improve performance (by serving from locations closer to the client) and security (by implementing OAI).
Web Root
So now that the easy part is out of the way, let’s dig into the fun stuff (Read: The hard part).
While the “right” method is the one that best fits your use case, I will point out which solutions I believe are particularly bad and which are my preferred method.
All of these methods support utilizing EC2 Auto Scaling and most of them would also entail the use of a User Data script to properly configure the servers on boot up.
In some cases the creation of an AMI may also be possible (or even advisable).
What are our options?
EFS (Elastic File System)
EFS is Amazon’s answer for NFS as a service. EFS is the solution that Amazon suggests in it’s reference architecture for WordPress. This reference architecture is implemented in many templates online.
One can utilize EFS for this purpose by attaching it as the webroot on your EC2 servers during spin up (In your Auto Scaling Group of course)
While EFS is the most obvious solution to handling the web root issues (Amazon even suggests it!), it’s also one of the worst possible options in my experience (Ask me how I know!).
Pros
- You can largely use WordPress as normal to install plugins/themes/upgrades. It’s an easy drop in solution requiring little further management on your part.
- There is no practical limit on the size of an EFS volume.
- The file system size scales elastically. There is no need to provision additional space.
- EFS can support 10+ GB per second of throughput (That’s a lot of throughput)
- Date is stored redundantly across multiple availability zones.
Cons
- Shares many of the disadvantages of a regular network attached file system.
- It’s incredibly expensive compared to other storage methods, like $300 expensive.
- Previously, EFS only supported expanding throughput by expanding the size of the volume (Often with a dummy file). Attaining a consistent throughput of 50 MiB/s meant storing at least a TB of data. The cost of this would be $300 at minimum. While EFS does support provisioned IOPs now, it costs $6 per MiB/s at minimum. This means you’d still be paying at minimum $300 for 50 MiB/s of throughput. Bit of a wash.
- It uses burst credits (Like T series EC2 instances). I really hope you reviewed the documentation closely! You may find your application works reasonably well without provisioned IOPS and a small disk size until you receive a consistent burst of traffic. When that happens you’ll find the performance completely tanks and be scrambling to figure out why.
- It has high latency. It’s about 3 times slower out of the box than EBS. There have been many different complaints about this.
- High latency in a web server is generally bad news bears. WordPress has a lot of small files that will be accessed.
- There are methods to work around this but that’s slapping a bandaid over an already expensive solution.
In short, EFS seems like a poor solution.
I’ve deployed a number of EFS based infrastructures and found the performance and trouble generally were not worth it.
Most of it’s benefits aren’t relevant for this use case, it’s poor latency adversely effects performance, and it’s expensive. The biggest benefit is it’s very easy to get going.
Self Hosted NFS/GlusterFS/Etc
Another option that’s similar to the above is simply hosting NFS, GlusterFS, or a similar network file system on your own.
Similar to EFS, one can attach the share as the webroot on your EC2 servers during spin up (In your Auto Scaling Group of course)
Pros
- You can largely use WordPress as normal to install plugins/themes/upgrades. It’s an easy drop in solution on the WordPress side.
- I’ve ready that many people have reported better performance and latency when compared to using EFS.
- It is likely to be cheaper than EFS for the given performance and storage space.
- Similar benefits when it comes to just dropping in and using WordPress as normal.
Cons
- Unless you’re intending to configure a multi-AZ NFS/GlusterFS setup, you’ve now introduced a pretty major single point of failure. This potentially mitigates the other work made to create a HA infrastructure.
- After considering the time to manage and monitor the system/s (particularly if you try to roll your own HA setup), it may end up even more expensive than simply using EFS.
- It’s still going to share many of the other problems with network file systems and will still likely have worse latency than EBS or instance store.
Self hosting your own NFS setup shares many of the same problems as EFS and adds even more of it’s own.
My conclusion is that this is likely a poor choice for a scalable/HA WordPress infrastructure.
Version Control It
At this point I feel that we start to get to some solutions that are not only less expensive but also add some additional features that can help make the WordPress act a bit more like a modern web app.
If you read my previous article (you read it right?) you’ll remember that the biggest issues are the user uploaded files (We solve that with the object storage) followed by the plugins, themes, and version of WordPress installed on the servers.
The idea here is to utilize php-composer in conjunction with WordPress Packagist and then utilize a Git repository for the composer.json. Then composer is used to install the required versions of your plugins and themes. Alternatively, one could also use wp-cli to accomplish something similar (or both can even be used together).
At this point, each time a new box is spun up (For example with your EC2 Auto Scaling Group) it is installed from a known configuration.
CI/CD tools can be used to update existing servers or you can do a blue/green deployment when updating and then rollover.
Pros
- Everything works as usual on the WordPress side (Uploading images, writing articles, users, etc), minus upgrading WordPress and installing plugins.
- More performant and (much cheaper) than other methods mentioned.
- Since you’re installing everything in an automated fashion, it becomes much easier to configure different environments for testing. For example, setting up a local development environment using Docker.
Cons
- End users can no longer install/update plugins/themes on production (It’s likely a good idea to prevent them from doing so with permissions). This is arguably a pro.
- Initial setup may be slightly more difficult than simply attaching EFS.
- Auto-scaling may take slightly longer depending on how the user-data scripts are implemented.
- There are occasionally plugins that write configs to local file systems which you’d want to look out for.
I’m of the opinion that if you are truly looking to setup a scalable, HA, and performant WordPress setup (and don’t want to spend a ton on the infrastructure) then this is likely where you should be looking.
If someone needs to install/test plugins this can be done in any of the other environments (Either on local dev or staging) before they are moved to production.
This method makes it far easier to duplicate the install for other environments (local dev, staging), supports CI/CD, and covers all the other bases (HA, scalable, performant).
Other Methods?
I’m certain there are other methods one might handle this.
One I’ve heard of handling is only allowing people to interact with a staging environment that is then used to create an AMI for auto-scaling in production, though I haven’t yet tested this myself.
Is there something else I missed? Are you handling this in another way? Don’t hesitate to share :).
Conclusion
Hosting WordPress in this fashion is not an easy task but it is doable with extensive consideration of how WordPress is managed and of the tools the AWS ecosystem provides you.
I hope you found this article informative and decide to share.
If you have any questions or comments, don’t hesitate to reach out in the comments. Thanks for reading!
Looking for someone to take care of this stuff for you? I understand completely 🙂
You can easily schedule a meeting with me at the bottom of the article.
Want to understand how I can help? Take a look at my article here.
Till next time.